






Authors: Zhi Zhou, Ming Yang, Jiang-Xin Shi, Lan-Zhe Guo, Yu-Feng Li. (Nanjing University)
视觉语言模型(Vision-Language Models,简称 VLMs)通过对齐视觉模态和文本模态,在各种下游任务中展现了强大的零样本泛化能力。具体来说,在处理某个下游任务时,只需提供类别空间的文本描述,视觉语言模型就能通过计算测试图像的图像嵌入与类别名称文本嵌入之间的余弦相似性,实现分类。为了进一步提升视觉语言模型在下游任务中的表现,一些研究开始探索小样本提示微调(Few-Shot Prompt Tuning),其目标是利用少量样本微调模型中的文本提示模版,从而提升模型在下游任务中的性能。大量研究表明,小样本提示微调技术可以有效提升视觉语言模型在已学习小样本类别上的泛化能力。然而,这种方法往往会削弱模型对小样本训练集中未见类别的表现,严重限制了其在实际应用中的广泛性。为了解决这个挑战,一种评估已知类别与未见类别性能调和平均数 (Harmonic Mean) 的性能评估指标,一定程度上解决了未见类别性能下降现象的评估问题并使研究人员逐步意识在这个问题的重要性。
我们通过研究发现,现有基于调和平均数的性能指标仅考虑了模型在已知类别和未知类别上的分类能力,而忽略了模型判断测试样本是否属于已知类别或未知类别的能力,导致评估结果不够全面。在实际应用中,视觉语言模型分类系统在分类之前无法获得样本是否属于微调时的已知类别或未见类别的先验信息。因此,即使模型在现有的调和平均数指标上表现优异,也可能由于无法准确区分未见类别与已知类别,从而在实际预测中产生较差的性能表现。为了解决这一问题,我们提出了一种更加符合实际场景的设置,称为“开放世界提示微调”(Open-World Prompt Tuning,简称 OPT)。在这种设置下,视觉语言模型基于少量训练数据进行微调,并在测试阶段对已见类别和未见类别的混合数据进行评估,从而更全面地衡量模型在现实场景中的表现。
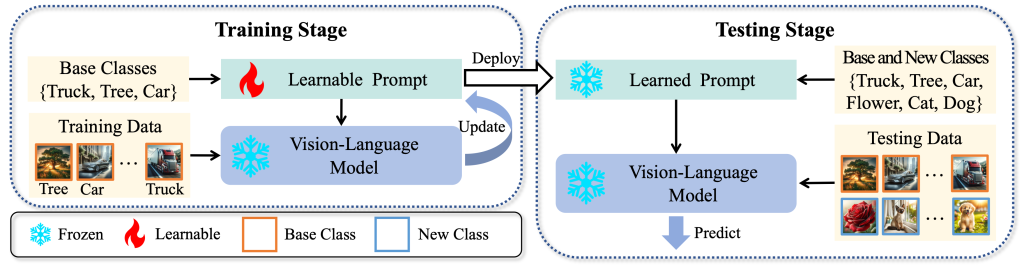
针对 OPT 问题设置,我们提出了一种基于分布外检测技术(Out-of-Distribution Detection, OOD)的提示学习微调框架,称为分解提示微调(Decomposed Prompt Tuning, DePT)。该框架将分布外检测技术引入视觉语言模型的提示微调中。当测试样本到来时,DePT 首先利用分布外检测技术判断测试样本是否属于微调时的已见类别。如果是已见类别,样本将由微调后的视觉语言模型进行分类;如果是未见类别,样本则交由原始的视觉语言模型进行分类。这样有效避免了微调后的模型在处理未见类别时性能下降的问题。我们从理论上证明了基于 DePT 框架的模型相比原始模型能够显著提升性能。同时,多个实验结果也验证了 DePT 框架的有效性。通过这一工作,我们从理论和经验层面展示了分布外检测技术在提升视觉语言模型提示微调效果中的作用,并为进一步的算法设计提供了新的启发。
基于上述理论和实验证据,我们提出了一种基于分解的提示学习方法(Decomposed Context Optimization, DeCoOp)。具体来说,我们设计了一种基于文本提示的分布外检测技术,旨在进一步增强经过微调的视觉语言模型在区分已知类别与未见类别上的性能,并结合 DePT 框架的思路进行样本分类。这一过程面临的主要挑战在于:如何仅使用少量已知类别的数据有效微调提示模板,从而构建分布外检测模型?为此,我们提出了一种基于留出策略的提示微调机制(Leave-Out Strategy)。在该机制中,首先将类别空间划分为 K 份,并训练 K 个基于提示微调的分布外检测器。每个分布外检测器将其中 K - 1 份类别空间作为已知类别集合进行训练,剩余的 1 份类别空间则作为模拟的未见类别集合。同时,每个检测器在其对应的已知类别集合上微调提示模型用于分类。在推理过程中,K 个分布外检测器会同时对测试样本进行检测。如果有一个或多个检测器将该样本判定为已知类别,则使用判定置信度最高的检测器对应的分类模型进行分类。如果所有检测器均拒绝该样本,则将其交由原始视觉语言模型进行分类。实验结果显示,所提出的 DeCoOp 方法在 11 个常用数据集以及多种模型规模上均获得了最佳平均性能,充分证明了该方法的优越性。

总而言之,本研究发现现有的视觉语言模型小样本提示微调技术的评估指标存在不足,并提出了一种新颖的评估指标以修正这一问题。此外,本研究将分布外检测引入提示微调技术中,通过一个通用框架 DePT 和一个具体的训练方法 DeCoOp,有效验证了这一思路的可行性。
Comments | NOTHING